งานวิจัยการสร้างแผนที่แนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นด้วยระบบสารสนเทศภูมิศาสตร์ (พ.ศ. 2545)
ผลลัพธ์การวิจัย ได้แก่ แผนที่แนวแบ่งเขตภาษาแสดงในรูปเส้นและเขตภาษา 1 แผ่น และ ข้อมูลร้อยละการใช้ภาษาไทยถิ่นกลางที่พบบริเวณแนวแบ่งระหว่างอำเภอคอบคลุมทั่วประเทศ
ข้อมูลคำศัพท์ที่นำมาใช้ในงานวิจัยนี้รวบรวมจากการตอบแบบสอบถามของตัวแทนผู้บอกภาษาในระดับตำบลทั่วประเทศ เมื่อ พ.ศ. 2545 – 2546 ใน ‘โครงการพัฒนาแผนที่ภาษาไทยถิ่นด้วยระบบสารสนเทศภูมิศาสตร์’ จากนั้น นำข้อมูลที่ได้มาจัดเก็บในรูปฐานข้อมูลแผนที่ภายใต้ระบบสารสนเทศภูมิศาสตร์ (Geographic Information System – GIS) และจัดทำเป็นแผนที่เชิงเลข (digital data)
ผู้วิจัย ‘งานวิจัยการสร้างแผนที่แนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นด้วยระบบสารสนเทศภูมิศาสตร์’
ผู้วิจัยและรับผิดชอบโครงการ:
- ผู้ช่วยศาสตราจารย์ ดร. ศิริวิไล ธีระโรจนารัตน์ (ตำแหน่งในขณะดำเนินโครงการวิจัย) ภาควิชาภูมิศาสตร์ คณะอักษรศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย
ที่ปรึกษา:
- ผู้ช่วยศาสตราจารย์ ดร. ม.ร.ว. กัลยา ติงศภัทิย์ ภาควิชาภาษาศาสตร์คณะอักษรศาสตร์จุฬาลงกรณ์มหาวิทยาลัย
งานวิจัยการสร้างแผนที่แนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นด้วยระบบสารสนเทศภูมิศาสตร์: ความเป็นมา วัตถุประสงค์ การดำเนินการและผลลัพธ์
ความสำคัญและความเป็นมาของการวิจัย
ภาษาไทยถิ่นจัดเป็นปรากฏการณ์อย่างหนึ่งบนพื้นที่ แสดงให้เห็นถึงถิ่นที่อยู่ของผู้พูดที่แตกต่างกันออกไปตามสภาพแวดล้อมทางภูมิศาสตร์และโลกทัศน์ของแต่ละท้องถิ่น เป็นความภาคภูมิใจและเป็นเอกลักษณ์เฉพาะของแต่ละท้องถิ่น ในประเทศไทยนั้นได้มีการนำเสนอผลการศึกษาวิจัยภาษาถิ่นด้วยแผนที่มาแล้วกว่า 30 ปี อย่างไรก็ดี จนถึงปัจจุบันการศึกษาและงานวิจัยที่เกี่ยวข้องกับการสร้างแผนที่ภาษาไทยถิ่นในประเทศไทยยังมีความถูกต้องแม่นยำเชิงพื้นที่ไม่มากนัก เท่าที่ผ่านมาการสร้างแผนที่ภาษามักสร้างขึ้นบนแผนที่แผ่นกระดาษ ใช้มือในการกำหนดจุดแสดงตำแหน่งการเก็บข้อมูล และลากเส้นแบ่งเขตภาษา (isogloss) หรือแนวแบ่งเขตภาษา (boundary) อย่างคร่าว ๆ ด้วยสายตา และแสดงผลแผนที่อย่างหยาบ ๆ การทำงานในลักษณะนี้ล้วนมีผลทำให้ความน่าเชื่อถือของแผนที่ผลลัพธ์ลดลง
ในปี 2545 ผู้วิจัยได้มีโอกาสร่วมงานในฐานะผู้ร่วมวิจัยใน “โครงการพัฒนาฐานข้อมูลคำศัพท์ภาษาไทยถิ่น” ซึ่งเป็นความร่วมมือระหว่างสำนักงานคณะกรรมการวัฒนธรรมแห่งชาติ กระทรวงวัฒนธรรม และ ศูนย์วิจัยความหลากหลายทางภาษา ภาควิชาภาษาศาสตร์ คณะอักษรศาสตร์ รับผิดชอบโครงการโดย ผู้ช่วยศาสตราจารย์ ดร. ม.ร.ว.กัลยา ติงศภัทิย์ โครงการดังกล่าวมีจุดมุ่งหมายในการทำการรวบรวมและบันทึกคำศัพท์ที่ปรากฏอยู่ในภาษาไทยถิ่นทั่วประเทศ ข้อมูลคำศัพท์ได้ดำเนินการเก็บข้อมูลในช่วงปี พ.ศ. 2545-2546 ประกอบด้วยหน่วยอรรถจำนวน 170 หน่วยอรรถ จากข้อมูลในระดับตำบลทั่วประเทศ ในฐานะนักภูมิศาสตร์ ผู้วิจัยมีหน้าที่รับผิดชอบในส่วนของการจัดเก็บและจัดทำฐานข้อมูลภูมิศาสตร์คำศัพท์ด้วยระบบสารสนเทศภูมิศาสตร์ รวมทั้งการนำเสนอผลในรูปของแผนที่แสดงการกระจายของคำศัพท์ โครงการดังกล่าวจัดได้ว่าเป็นโครงการนำร่องที่ได้มีการนำระบบสารสนเทศภูมิศาสตร์มาใช้ในการรวบรวม จัดเก็บและจัดทำฐานข้อมูลภูมิศาสตร์คำศัพท์ขนาดใหญ่ ข้อมูลที่ได้เป็นแผนที่เชิงเลขทำให้ง่ายต่อการปรับแก้และการผลิตแผนที่ นอกจากนี้ ผลลัพธ์โครงการยังแสดงให้เห็นถึงความหลากหลายของการกระจายของคำศัพท์ในบริเวณต่าง ๆ บนแผนที่ และประสิทธิภาพของระบบสารสนเทศภูมิศาสตร์ (Geographic Information System – GIS) ในการจัดการข้อมูลภูมิศาสตร์คำศัพท์ โครงการดังกล่าวทำให้ผู้วิจัยเกิดความสนใจในการศึกษาต่อยอด โดยมีจุดหมายสุดท้ายที่จะนำข้อมูลคำศัพท์ดังกล่าวมาหาแนวแบ่งเขตภาษาไทยถิ่นต่าง ๆ ของประเทศไทยในอนาคต
การวิจัยนี้จึงเป็นจุดเริ่มต้นของงานวิจัยต่อยอด โดยมีจุดมุ่งหมายหลักในการนำระบบสารสนเทศภูมิศาสตร์ มาบูรณาการร่วมกับวิธีการทางภาษาศาสตร์ที่มีอยู่เดิมเพื่อช่วยวิเคราะห์การกำหนดแนวแบ่งเขตภาษาถิ่น กรอบการศึกษาเน้นการหาแนวแบ่งเขตภาษาถิ่นระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่น ๆ ของประเทศไทย งานวิจัยได้ดำเนินงานในระหว่าง เมษายน 2551 – เมษายน 2552 โดยได้รับเงินทุนสนับสนุนการวิจัยจาก คณะอักษรศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย และ ทุนพัฒนาอาจารย์ใหม่ กองทุนรัชดาภิเษกสมโภช จุฬาลงกรณ์มหาวิทยาลัย
วัตถุประสงค์การวิจัย
1. เพื่อศึกษาวิเคราะห์การกระจายของคำศัพท์ และแสดงผล (นำมาจัดทำ) ในรูปแผนที่เส้นแบ่งเขตคำศัพท์
2. เพื่อกำหนดแนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นโดยใช้คำศัพท์เป็นเกณฑ์และแสดงผลในรูปแผนที่แนวแบ่งเขตภาษา
3. เพื่อเปรียบเทียบว่าแนวแบ่งเขตภาษาไทยถิ่นกลางตามภูมิภาคภาษาถิ่นโดยใช้คำศัพทเป็นเกณฑ์จะเหมือนหรือแตกต่างจากแนวแบ่งเขตภูมิภาคทางภูมิศาสตร์มากน้อยเพียงไร
4. เพื่อนำเสนอทางเลือกใหม่ในการนำระบบสารสนเทศภูมิศาสตร์มาประยุกต์ร่วมกับวิธีการทางภาษาศาสตร์เพื่อช่วยวิเคราะห์การกำหนดแนวแบ่งเขตภาษาถิ่น
ขอบเขตการวิจัย
1. ศึกษาเฉพาะการกำหนดแนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นของประเทศไทยโดยใช้คำศัพท์เป็นเกณฑ์
2. พื้นที่วิจัยครอบคลุมข้อมูลในระดับตำบลของประเทศไทยทั่วประเทศ ยกเว้นเขตในจังหวัดกรุงเทพมหานคร
3. ในข้อเสนอของงานวิจัยนี้ ผู้วิจัยตั้งใจจะใช้การบูรณาการหลักการทางภูมิศาสตร์ ภาษาศาสตร์ และ การวิเคราะห์การตัดสินใจหลายเกณฑ์ (multi-criteria decision analysis) เพื่อการวิเคราะห์และจัดทำแผนที่แนวแบ่งเขตภาษา อย่างไรก็ตามหลังจากการวิเคราะห์ข้อมูลไประยะหนึ่งพบว่าไม่สามารถนำการวิเคราะห์การตัดสินใจหลายเกณฑ์มาใช้ด้วยได้เนื่องจากเหตุผลสำคัญคือข้อจำกัดในเรื่องความสมบูรณ์ของข้อมูล
ข้อกำหนดเบื้องต้น
1. ข้อมูลที่ใช้เป็นพื้นฐานในการวิจัย นำมาจากฐานข้อมูลภูมิศาสตร์คำศัพท์ใน”โครงการพัฒนาฐานข้อมูลคำศัพท์ภาษาไทยถิ่น” ซึ่งประกอบด้วยแผนที่เชิงเลข(digital map) แสดงการกระจายของคำศัพท์จำนวน 170 หน่วยอรรถ (ตำแหน่งเก็บข้อมูลคำศัพท์บนแผนที่จัดเก็บและแทนในรูปขอบเขตตำบล) และใช้ขอบเขตตำบลเป็นตัวแทนตำแหน่งเก็บข้อมูลคำศัพท์บนแผนที่
2. งานวิจัยศึกษาแนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่น คำว่า ภาษาไทยถิ่นอื่น ในที่นี้ หมายถึง ภาษาไทยถิ่นเหนือ ภาษาไทยถิ่นอิสาน ภาษาไทยถิ่นใต้ รวมถึงภาษาตระกูลอื่น
การดำเนินการวิจัย
การดำเนินการวิจัยแบ่งเป็น 3 ส่วนใหญ่ ๆ คือ การวิเคราะห์คำศัพท์ การกำหนดเส้นแบ่งเขตคำศัพท์ และ การกำหนดแนวแบ่งเขตคำศัพท์ การดำเนินการในส่วนแรก คือ การวิเคราะห์คำศัพท์ ซึ่งใช้วิธีการวิเคราะห์ตามแนวทางภาษาศาสตร์ที่ใช้อยู่เดิมเป็นหลัก สำหรับการดำเนินการในส่วนที่ 2 และ 3 หัวใจสำคัญของการดำเนินการจะเป็นการนำระบบสารสนเทศภูมิศาสตร์มาประยุกต์ใช้ มีขั้นตอนในส่วนที่ 2 และ 3 โดยสรุป ดังนี้
ในส่วนที่ 2 : ผลจากการวิเคราะห์และจัดกลุ่มคำศัพท์ในส่วนที่1 ได้แก่ กลุ่มคำศัพท์ของภาษาไทยถิ่นกลางและกลุ่มคำศัพท์ของภาษาไทยถิ่นอื่นของแต่ละหน่วยอรรถจะถูกนำมากำหนดและลงรหัส และแสดงผลในรูปแผนที่แสดงเส้นแบ่งเขตคำศัพท์
ในส่วนที่ 3 : การดำเนินการในส่วนนี้แบ่งได้เป็น 3 ขั้นตอนหลัก คือ (1) การวิเคราะห์การซ้อนทับข้อมูลเชิงพื้นที่ (2) การคำนวณร้อยละการใช้ภาษาไทยถิ่นจากกลุ่มศัพท์ที่จำแนกไว้ก่อนหน้านี้ และ (3) การกำหนดและลากแนวแบ่งเขตภาษา ทั้งนี้ การวิเคราะห์แนวแบ่งเขตภาษาถือเป็นหัวใจหลักของงานวิจัยนี้ แนวแบ่งเขตภาษาที่สร้างขึ้นเกิดจากการซ้อนทับเส้นแบ่งเขตคำศัพท์จำนวน 170 หน่วยอรรถ ด้วยฟังก์ชันในระบบสารสนเทศภูมิศาสตร์ และกำหนดแนวแบ่งเขตด้วยการลากแนวแบ่งภาษาจากบริเวณที่มีร้อยละของการใช้ศัพท์ทั้งสองถิ่นเท่า ๆ กัน คือ 50% การวิเคราะห์แนวแบ่งเขตภาษา ทำให้แบ่งเขตภาษาออกเป็น 2 เขต คือ เขตภาษาถิ่นไทยกลางกับเขตภาษาไทยถิ่นอื่น
ผลลัพธ์การวิจัย
ผลการวิเคราะห์นำเสนอผลในรูป
1) ‘แผนที่ซ้อนทับคำศัพท์’ ตามขอบเขตการปกครองระดับตำบล อำเภอ จังหวัด และภูมิภาคภูมิศาสตร์ รวมทั้งตารางสรุปบริเวณที่มีการใช้ภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นในระดับจังหวัดและภูมิภาค ผลลัพธ์ ‘แผนที่ซ้อนทับคำศัพท์’ ตามขอบเขตการปกครองระดับตำบล แสดงในภาพที่ 1
2) แผนที่แนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นแสดงในรูปเส้นและเขตภาษา ทั้งนี้ การลากแนวแบ่งเขตภาษาที่ใช้ ลากจากบริเวณที่มีการใช้ภาษาไทยถิ่นกลางตั้งแต่ 50%ขึ้นไปตามเส้นแบ่งเขตอำเภอ ผลลัพธ์แผนที่แนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นในรูปเส้นและเขตภาษา แสดงในภาพที่ 2 และ 3 ตามลำดับ
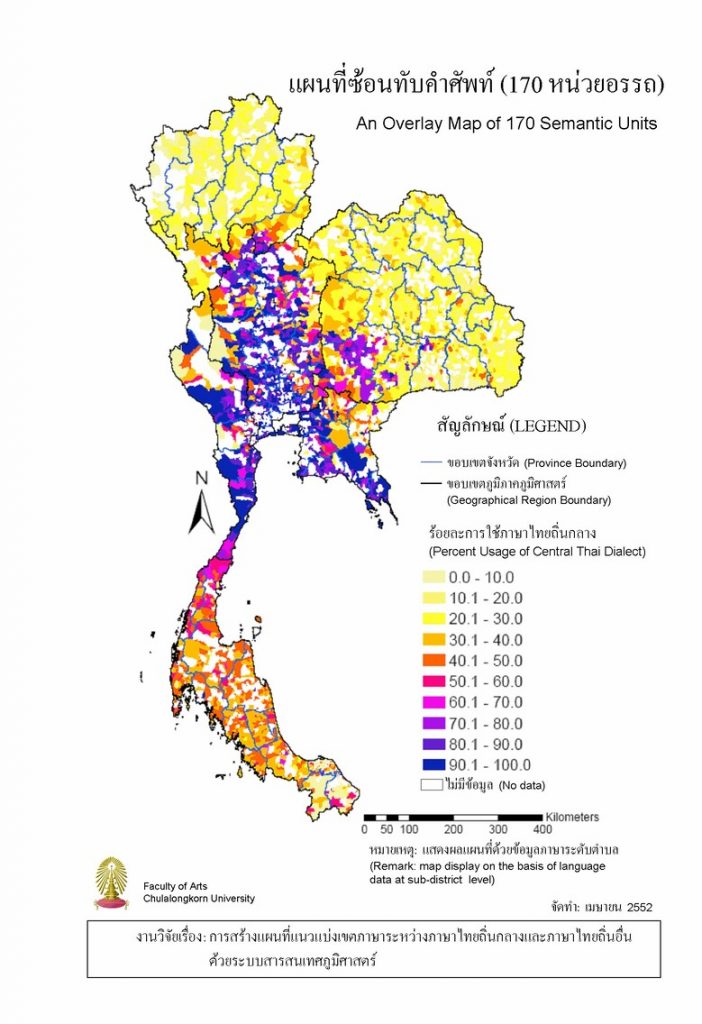
ภาพที่ 1 ‘แผนที่ซ้อนทับคำศัพท์’ ตามขอบเขตการปกครองระดับตำบล

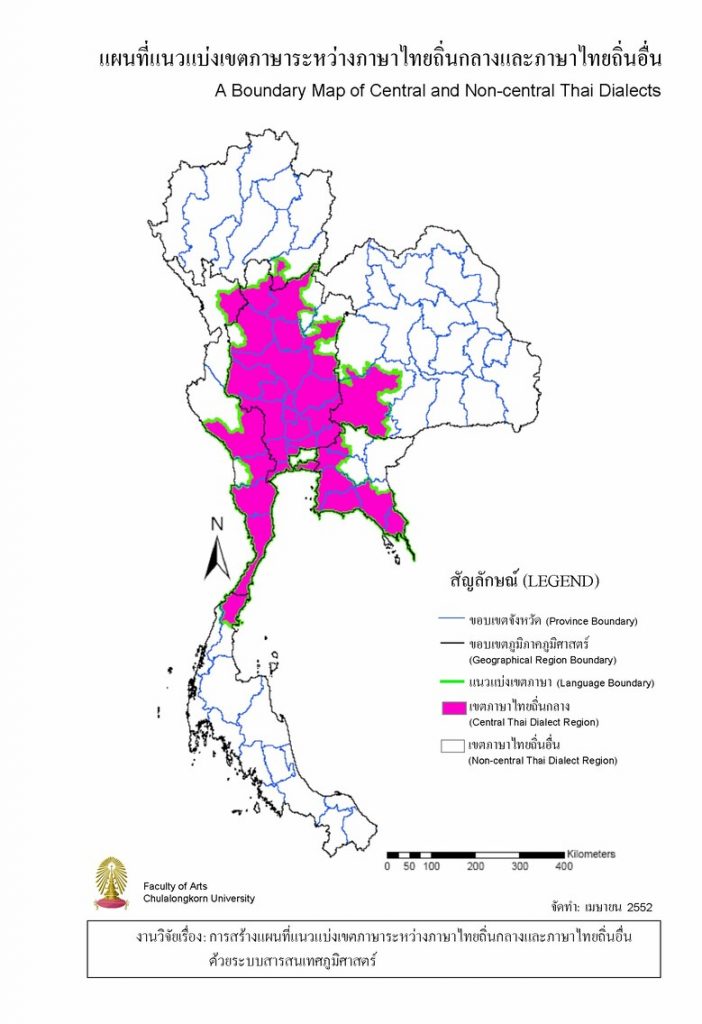
ภาพที่ 2 แผนที่แนวแบ่งเขตภาษาระหว่างภาษาไทยถิ่นกลางและภาษาไทยถิ่นอื่นในรูปเส้น (ซ้าย) และเขตภาษา (ขวา)